Performance
The performance (the speedup in particular) of magpar version 0.1 has been measured on a Compaq SC45 cluster consisting of 11 nodes Alpha Server ES45 with 4 Alpha processors (EV68 @ 1 GHz, 8 MB Cache/CPU) and 16 GB of shared memory each. The nodes are interconnected with a Quadrics switch, which provides a maximum MPI bandwidth of 600 MB/s. Since this machine has been shared with several other users, up to 24 processors have been available for speedup measurements.
The speedup has been measured as SP=t1/tP, where t1 is the execution time of the program for a given problem on a single processor and tP is the execution time for the same problem on P processors.
The energy minimization method, which uses the LMVM method of the TAO package, has been applied to calculate the nucleation field of FePt nanoparticles. The timing results are summarized in the following figure:
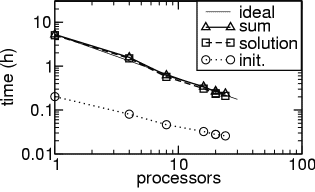
Speedup of initialization, solution, and total execution time of the parallel energy minimization algorithm (TAO) on an AlphaServer.
processors | CPU time (h) | speedup |
|---|---|---|
initialization |
|
|
1 | 0.202 | 1.00 |
4 | 0.080 | 2.52 |
8 | 0.046 | 4.38 |
16 | 0.032 | 6.26 |
20 | 0.027 | 7.33 |
24 | 0.025 | 7.86 |
solution |
|
|
1 | 5.047 | 1.00 |
4 | 1.500 | 3.36 |
8 | 0.568 | 8.87 |
16 | 0.307 | 16.41 |
20 | 0.233 | 21.57 |
24 | 0.210 | 23.97 |
total |
|
|
1 | 5.249 | 1.00 |
4 | 1.581 | 3.32 |
8 | 0.615 | 8.53 |
16 | 0.339 | 15.44 |
20 | 0.261 | 20.06 |
24 | 0.236 | 22.20 |
On 8 and 16 processors we find a "superlinear" behavior of the solution part of the application. This is a well known phenomenon in parallel computing and can be attributed to caching effects. As the same total amount of data is distributed over more processors, the relative amount decreases and may reach a size, where it fits into the fast cache memory of modern computer architectures. As a result, the data need not be fetched from the main memory (which is a lot slower than the cache memory) and the calculations are completed a lot faster.
The parallel time integration using PVODE is not as efficiently parallelized as the TAO package, which is shown in the following figure:
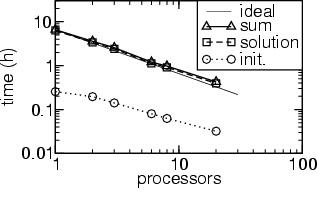
Speedup of initialization, solution, and total execution time of the parallel time integration (PVODE) on an AlphaServer.
processors | CPU time (h) | speedup |
|---|---|---|
initialization |
|
|
1 | 0.255 | 1.00 |
2 | 0.196 | 1.30 |
3 | 0.141 | 1.81 |
6 | 0.080 | 3.19 |
8 | 0.062 | 4.07 |
16 | 0.037 | 6.73 |
20 | 0.032 | 7.96 |
solution |
|
|
1 | 6.309 | 1.00 |
2 | 3.379 | 1.86 |
3 | 2.416 | 2.61 |
6 | 1.120 | 5.63 |
8 | 0.913 | 6.91 |
16 | 0.451 | 13.98 |
20 | 0.393 | 16.03 |
total |
|
|
1 | 6.565 | 1.00 |
2 | 3.576 | 1.83 |
3 | 2.557 | 2.56 |
6 | 1.200 | 5.46 |
8 | 0.975 | 6.72 |
16 | 0.489 | 13.42 |
20 | 0.425 | 15.42 |
For comparison, the next figure shows the speedup obtained on a Beowulf type cluster of 900 MHz AMD PCs running Linux (for a different problem). These machines are linked with a standard switched 100 MBit Ethernet network.
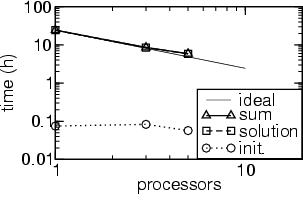
Speedup of initialization, solution, and total execution time of the parallel time integration (PVODE) on a Beowulf type AMD cluster.
processors | CPU time (h) | speedup |
|---|---|---|
initialization |
|
|
1 | 0.075 | 1.00 |
3 | 0.083 | 0.91 |
5 | 0.057 | 1.32 |
solution |
|
|
1 | 24.334 | 1.00 |
3 | 8.5059 | 2.86 |
5 | 5.8314 | 4.17 |
total |
|
|
1 | 24.41 | 1.00 |
3 | 8.589 | 2.84 |
5 | 5.889 | 4.15 |